우리는 항상 아이디어에 굶주려 있습니다. 저또한 아이디어를 무엇을 만들어야하나 항상 고민을 하고 있었는데, 기술사공부를 하면서 봐왔던 아이디어 기법인 TRIZ와 SCAMPER기법을 섞은 데스크탑 어플리케이션이 있으면 좋겠다 생각했었습니다. 대 AI시대 gemini API를 이용해서 이를 고도화하면 좋은 어플리케이션이 나오지 않을까 한 단계 생각이 퍼져나갔고 한번 만들어 보았습니다.
* 무단배포는 금지합니다.(댓글달아주세용) * 기능에 커스터마이징이 필요하시다면 댓글달아주세용
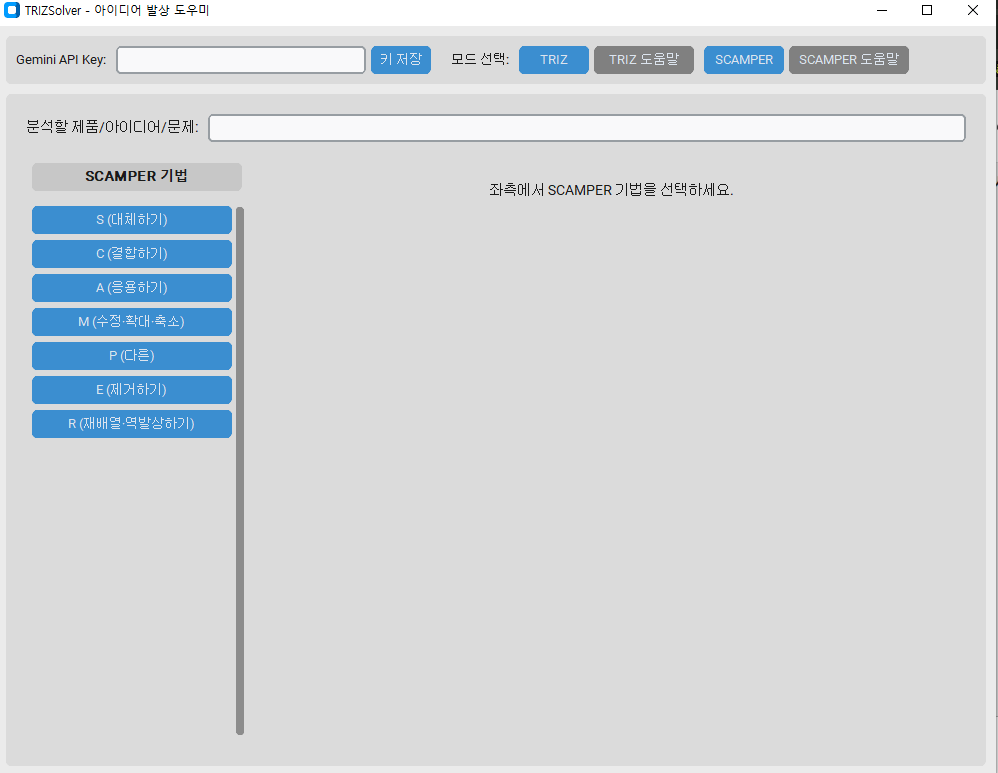
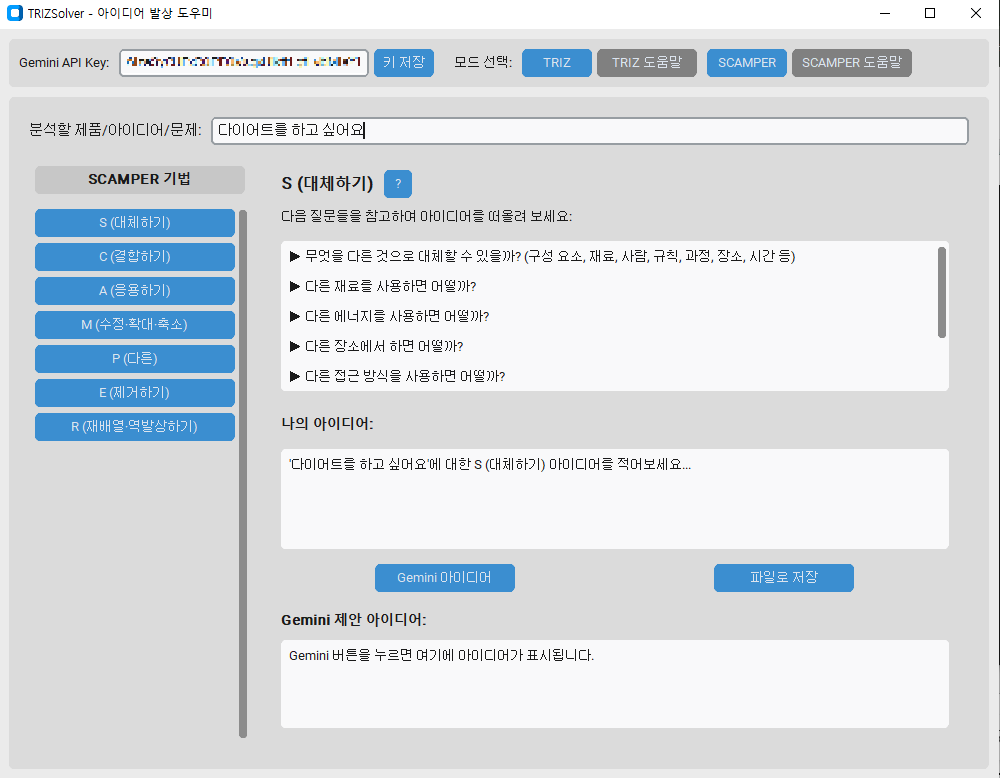
사용법 평소에는 소스코드를 올리지만 구조가 단일 코드 구조가 아니어서 별도의 사용방법을 올리겠습니다.
기술사공부를 하다가 평소 gemini AI와의 대화(Live)로 연습을 하는데 얘한테 input source로 제가 공부하고 있는 파일을 주고 싶어서 만들어 보았습니다. exe로 만들까 하다가 cli기반이고, 파라미터들로 직접조정하는게 좋을거 같다는 것과, 어짜피 python을 기반으로 exe를 만들면 너무 느려지기 때문에, 코드로만 배포합니다. 하단에 사용법에 코드 실행방법까지 자세하게 표기하겠습니다.
* 무단배포는 금지합니다.(댓글달아주세용) * 기능에 커스터마이징이 필요하시다면 댓글달아주세용
사용법
import tkinter as tk
from tkinter import scrolledtext, OptionMenu, StringVar, messagebox, Frame, Label
import re
import json
import os
from datetime import datetime
# --- 상수 정의 ---
PLACEHOLDER_PREFIX = "__COMMENT_KILLER_STR_LITERAL_"
PLACEHOLDER_SUFFIX = "__"
DEFAULT_LANGUAGES_FILE = "languages.json"
BACKUP_DIR = "comment_killer_backups" # 백업 파일 저장 디렉토리
LOG_FILE = os.path.join(BACKUP_DIR, "comment_killer_processing_log.txt") # 로그 파일 경로
# --- 언어 정의 로드 함수 (이전과 동일) ---
def load_language_definitions(filepath=DEFAULT_LANGUAGES_FILE):
try:
with open(filepath, 'r', encoding='utf-8') as f:
definitions = json.load(f)
return definitions
except FileNotFoundError:
messagebox.showerror("파일 오류", f"언어 정의 파일({filepath})을 찾을 수 없습니다.")
return {}
except json.JSONDecodeError:
messagebox.showerror("JSON 오류", f"언어 정의 파일({filepath})의 형식이 잘못되었습니다.")
return {}
except Exception as e:
messagebox.showerror("로드 오류", f"언어 정의 파일({filepath}) 로드 중 오류: {e}")
return {}
# --- 스마트 주석 제거 함수 (이전과 동일) ---
def remove_comments_smarter(code, language_name, all_language_definitions):
if language_name not in all_language_definitions:
messagebox.showerror("오류", f"'{language_name}' 언어는 아직 지원되지 않습니다 (정의 파일 확인 필요).")
return code
lang_spec = all_language_definitions[language_name]
string_patterns = lang_spec.get("strings", [])
comment_patterns = lang_spec.get("comments", [])
extracted_strings = []
current_code = code
placeholder_idx_counter = 0
if string_patterns:
for str_pattern_regex in string_patterns:
processed_parts = []
last_end_pos = 0
for match in re.finditer(str_pattern_regex, current_code):
start_match, end_match = match.span()
processed_parts.append(current_code[last_end_pos:start_match])
original_string = match.group(0)
extracted_strings.append(original_string)
placeholder = f"{PLACEHOLDER_PREFIX}{placeholder_idx_counter}{PLACEHOLDER_SUFFIX}"
processed_parts.append(placeholder)
placeholder_idx_counter += 1
last_end_pos = end_match
processed_parts.append(current_code[last_end_pos:])
current_code = "".join(processed_parts)
code_with_strings_replaced = current_code
for _, comment_pattern_regex in comment_patterns:
code_with_strings_replaced = re.sub(comment_pattern_regex, "", code_with_strings_replaced)
final_code = code_with_strings_replaced
for i in range(len(extracted_strings) - 1, -1, -1):
placeholder_to_restore = f"{PLACEHOLDER_PREFIX}{i}{PLACEHOLDER_SUFFIX}"
final_code = final_code.replace(placeholder_to_restore, extracted_strings[i], 1)
lines = final_code.splitlines()
non_empty_lines = [line for line in lines if line.strip()]
processed_code_final = "\n".join(non_empty_lines)
return processed_code_final
# --- 백업 디렉토리 및 로그 파일 준비 함수 ---
def ensure_backup_infrastructure():
"""백업 디렉토리와 초기 로그 파일을 준비합니다."""
if not os.path.exists(BACKUP_DIR):
try:
os.makedirs(BACKUP_DIR)
except OSError as e:
messagebox.showerror("백업 오류", f"백업 디렉토리 생성 실패: {BACKUP_DIR}\n{e}")
return False # 디렉토리 생성 실패
# 로그 파일이 없으면 헤더와 함께 생성
if not os.path.exists(LOG_FILE):
try:
with open(LOG_FILE, "w", encoding="utf-8") as logf:
logf.write("CommentKiller 처리 및 백업 로그\n")
logf.write("=" * 40 + "\n")
except Exception as e:
# 로그 파일 생성 실패는 치명적이지 않으므로 경고만 표시
messagebox.showwarning("로그 오류", f"로그 파일 생성 실패: {LOG_FILE}\n{e}")
return True # 인프라 준비 완료 (또는 디렉토리는 이미 존재)
# --- CommentKiller 애플리케이션 UI 클래스 (수정됨) ---
class CommentKillerApp:
def __init__(self, master):
self.master = master
master.title("CommentKiller - 주석 제거기 (백업 기능)")
master.geometry("900x650") # 높이 약간 늘림 (필요시)
self.language_definitions = load_language_definitions()
self.backup_infra_ok = ensure_backup_infrastructure() # 백업 인프라 준비
# --- UI 요소들 (이전과 동일하게 설정) ---
top_frame = Frame(master, pady=10)
top_frame.pack(fill="x", padx=10)
Label(top_frame, text="프로그래밍 언어 선택:", padx=5).pack(side="left")
self.language_var = StringVar(master)
lang_keys = list(self.language_definitions.keys())
if lang_keys:
self.language_var.set(lang_keys[0])
self.language_menu = OptionMenu(top_frame, self.language_var, *lang_keys)
else:
self.language_var.set("정의된 언어 없음")
self.language_menu = OptionMenu(top_frame, self.language_var, "정의된 언어 없음")
self.language_menu.pack(side="left", padx=5)
text_frame = Frame(master)
text_frame.pack(fill="both", expand=True, padx=10, pady=5)
input_frame = Frame(text_frame)
input_frame.pack(side="left", fill="both", expand=True, padx=(0, 5))
Label(input_frame, text="주석이 있는 원본 코드:", pady=5).pack(anchor="w")
self.input_text = scrolledtext.ScrolledText(input_frame, wrap=tk.WORD, height=15, undo=True)
self.input_text.pack(fill="both", expand=True)
output_frame = Frame(text_frame)
output_frame.pack(side="right", fill="both", expand=True, padx=(5, 0))
Label(output_frame, text="주석 제거된 코드:", pady=5).pack(anchor="w")
self.output_text = scrolledtext.ScrolledText(output_frame, wrap=tk.WORD, height=15, undo=True)
self.output_text.pack(fill="both", expand=True)
self.output_text.config(state=tk.DISABLED)
bottom_frame = Frame(master, pady=10)
bottom_frame.pack(fill="x")
self.remove_button = tk.Button(bottom_frame, text="주석 제거 실행!", command=self.process_remove_comments, width=20, height=2)
self.remove_button.pack()
def process_remove_comments(self):
if not self.backup_infra_ok:
messagebox.showerror("오류", "백업 시스템이 준비되지 않아 처리를 중단합니다.\n프로그램을 재시작하거나 폴더 권한을 확인해주세요.")
return
original_code_full = self.input_text.get("1.0", tk.END) # 백업을 위해 전체 텍스트 가져오기 (마지막 개행 포함)
source_code_to_process = original_code_full.strip() # 처리를 위해 앞뒤 공백 제거
selected_language = self.language_var.get()
if not source_code_to_process:
messagebox.showwarning("입력 필요", "제거할 코드를 좌측에 입력해주세요.")
return
if selected_language == "정의된 언어 없음" or not self.language_definitions:
messagebox.showwarning("언어 문제", "선택할 언어가 없거나 언어 정의 파일을 불러오지 못했습니다.")
return
# --- 백업 로직 시작 ---
backup_info_for_user = ""
backup_filename_leaf = ""
try:
# 파일 이름에 사용할 안전한 언어 이름 생성 (특수문자 제거)
safe_lang_name = "".join(c if c.isalnum() else "_" for c in selected_language)
timestamp = datetime.now().strftime("%Y%m%d_%H%M%S_%f")[:-3] # 밀리초까지
backup_filename_leaf = f"backup_{timestamp}_{safe_lang_name}.txt.back"
backup_filepath = os.path.join(BACKUP_DIR, backup_filename_leaf)
with open(backup_filepath, "w", encoding="utf-8") as bf:
bf.write(original_code_full) # 원본 전체 내용 저장
# 로그 파일에 기록
try:
with open(LOG_FILE, "a", encoding="utf-8") as logf:
log_entry = (f"{datetime.now().strftime('%Y-%m-%d %H:%M:%S')} - "
f"백업 파일: {backup_filename_leaf}, 언어: {selected_language}\n")
logf.write(log_entry)
except Exception as log_e:
# 로그 기록 실패는 경고만 표시, 주 기능에 영향 주지 않음
messagebox.showwarning("로그 기록 오류", f"백업 로그 기록 중 오류 발생: {log_e}")
backup_info_for_user = (f"\n\n[백업 성공]\n"
f"원본이 '{backup_filename_leaf}'로 저장되었습니다.\n"
f"(저장 위치: {os.path.abspath(BACKUP_DIR)})")
except Exception as e:
backup_error_details = f"원본 코드 백업 중 오류 발생:\n{e}"
messagebox.showwarning("백업 오류", backup_error_details) # 백업 실패 시 즉시 알림
backup_info_for_user = f"\n\n[백업 실패]\n{backup_error_details}"
# --- 백업 로직 끝 ---
# 주석 제거 로직 실행
cleaned_code = remove_comments_smarter(source_code_to_process, selected_language, self.language_definitions)
self.output_text.config(state=tk.NORMAL)
self.output_text.delete("1.0", tk.END)
self.output_text.insert(tk.INSERT, cleaned_code)
self.output_text.config(state=tk.DISABLED)
# 최종 결과 메시지
result_summary = ""
if source_code_to_process and not cleaned_code.strip() and source_code_to_process.strip():
result_summary = "모든 내용(주석 포함)이 제거되었거나 입력이 주석으로만 이루어져 있었습니다."
elif source_code_to_process and cleaned_code.strip():
result_summary = f"'{selected_language}' 언어의 주석이 성공적으로 제거되었습니다!"
else: # 입력이 처음부터 비어있었던 경우 (위에서 이미 처리했지만 방어적으로)
result_summary = "처리할 코드가 없었습니다."
messagebox.showinfo("처리 결과", result_summary + backup_info_for_user)
# --- 메인 프로그램 실행 부분 (이전과 동일) ---
if __name__ == "__main__":
root = tk.Tk()
app = CommentKillerApp(root)
root.mainloop()
기술사공부를 하다가 평소 gemini AI와의 대화(Live)로 연습을 하는데 얘한테 input source로 제가 공부하고 있는 파일을 주고 싶어서 만들어 보았습니다. exe로 만들까 하다가 cli기반이고, 파라미터들로 직접조정하는게 좋을거 같다는 것과, 어짜피 python을 기반으로 exe를 만들면 너무 느려지기 때문에, 코드로만 배포합니다. 하단에 사용법에 코드 실행방법까지 자세하게 표기하겠습니다.
* 무단배포는 금지합니다.(댓글달아주세용) * 기능에 커스터마이징이 필요하시다면 댓글달아주세용
사용법
# ==============================================================================
# XLS2JSON: Excel to JSON Converter
# ==============================================================================
#
# 설명:
# 이 스크립트는 Excel 파일(.xlsx, .xls)을 읽어 JSON 형식으로 변환하는
# 명령줄 인터페이스(CLI) 도구입니다. 데이터 시작 위치를 자동으로 감지하며,
# 특정 시트 또는 모든 시트를 변환하고, 결과를 콘솔 또는 파일로 출력할 수 있습니다.
# 여러 시트를 처리할 때 진행률 표시줄을 보여줍니다.
#
# 필요한 라이브러리 설치:
# pip install pandas openpyxl tqdm
#
# 기본 사용법:
# python xls2json.py <입력_Excel_파일경로> [옵션]
#
# 옵션:
# <입력_Excel_파일경로> : 변환할 Excel 파일의 경로 (필수)
#
# -o, --output <출력_파일경로> :
# 변환된 JSON 결과를 저장할 파일 경로입니다.
# 지정하지 않으면 결과가 콘솔(표준 출력)에 표시됩니다.
# 예: -o result.json
#
# -s, --sheet <시트_이름_또는_인덱스> :
# 변환할 특정 시트의 이름(문자열) 또는 0부터 시작하는 인덱스(숫자)입니다.
# 기본값은 0 (첫 번째 시트)입니다.
# --all-sheets 옵션이 사용되면 이 옵션은 무시됩니다.
# 예: -s "데이터 시트"
# 예: -s 1 (두 번째 시트를 의미)
#
# -a, --all-sheets :
# Excel 파일 내의 모든 시트를 변환합니다.
# 이 옵션을 사용하면 결과 JSON은 각 시트 이름을 키로 가지는 객체 형태가 됩니다.
# 예: {"Sheet1": [...], "Sheet2": [...]}
#
# 실행 예시:
# # 1. 첫 번째 시트를 콘솔에 출력
# python xls2json.py data.xlsx
#
# # 2. '매출데이터' 시트를 result.json 파일로 저장
# python xls2json.py data.xlsx -s "매출데이터" -o result.json
#
# # 3. 두 번째 시트(인덱스 1)를 console_output.json 파일로 저장
# python xls2json.py data.xlsx -s 1 -o console_output.json
#
# # 4. 모든 시트를 all_sheets.json 파일로 저장 (시트 이름별로 구분됨)
# python xls2json.py data.xlsx -a -o all_sheets.json
#
# ==============================================================================
import pandas as pd
import argparse
import sys
import json
import os
from tqdm import tqdm
# --- 이하 코드는 이전과 동일 ---
def find_and_process_data(df):
"""
데이터프레임에서 데이터 시작 위치를 찾아 처리하고,
첫 행을 헤더로 사용하여 Python 객체 리스트로 변환합니다.
"""
df_processed = df.dropna(how='all').dropna(how='all', axis=1)
if df_processed.empty:
return []
new_header = df_processed.iloc[0].astype(str)
df_processed = df_processed[1:]
df_processed.columns = new_header
df_processed = df_processed.reset_index(drop=True)
df_processed = df_processed.where(pd.notnull(df_processed), None)
return df_processed.to_dict(orient='records')
def convert_single_sheet_to_json(file_path, sheet_name=0):
"""
Excel 파일의 지정된 단일 시트를 읽어 자동 감지 후 JSON 문자열로 변환합니다.
"""
try:
df = pd.read_excel(file_path, sheet_name=sheet_name, header=None, engine='openpyxl')
processed_data = find_and_process_data(df)
json_data = json.dumps(processed_data, indent=4, ensure_ascii=False)
return json_data
except FileNotFoundError:
print(f"오류: 파일을 찾을 수 없습니다 - {file_path}", file=sys.stderr)
return None
except ValueError as ve:
print(f"오류: 시트 '{sheet_name}' 처리 중 오류 발생. 시트 이름/인덱스를 확인하세요. 에러: {ve}", file=sys.stderr)
return None
except Exception as e:
print(f"오류: 단일 시트 처리 중 예외 발생 ({type(e).__name__}) - {e}", file=sys.stderr)
return None
def convert_all_sheets_to_json(file_path):
"""
Excel 파일의 모든 시트를 읽어 자동 감지 후 시트 이름을 키로 하는 JSON 객체 문자열로 변환합니다.
"""
try:
all_sheets_df_map = pd.read_excel(file_path, sheet_name=None, header=None, engine='openpyxl')
all_sheets_data = {}
print("시트 처리 중...", file=sys.stderr)
for sheet_name, df in tqdm(all_sheets_df_map.items(), desc="Processing sheets", unit="sheet", leave=False):
try:
processed_data = find_and_process_data(df)
all_sheets_data[sheet_name] = processed_data
except Exception as e:
print(f"\n경고: 시트 '{sheet_name}' 처리 중 오류 발생하여 건너뜁니다 ({type(e).__name__}) - {e}", file=sys.stderr)
all_sheets_data[sheet_name] = {"error": f"Failed to process sheet: {e}"}
json_data = json.dumps(all_sheets_data, indent=4, ensure_ascii=False)
return json_data
except FileNotFoundError:
print(f"오류: 파일을 찾을 수 없습니다 - {file_path}", file=sys.stderr)
return None
except Exception as e:
print(f"오류: 모든 시트 처리 중 예외 발생 ({type(e).__name__}) - {e}", file=sys.stderr)
return None
def save_to_file(data, output_file):
"""
주어진 데이터를 지정된 파일 경로에 UTF-8 인코딩으로 저장합니다.
"""
try:
output_dir = os.path.dirname(output_file)
if output_dir and not os.path.exists(output_dir):
os.makedirs(output_dir, exist_ok=True)
with open(output_file, 'w', encoding='utf-8') as f:
f.write(data)
return True
except IOError as e:
print(f"오류: 파일 '{output_file}'에 쓰는 중 오류 발생 - {e}", file=sys.stderr)
return False
except Exception as e:
print(f"오류: 파일 저장 중 예기치 않은 오류 발생 ({type(e).__name__}) - {e}", file=sys.stderr)
return False
def main():
parser = argparse.ArgumentParser(
description="XLS2JSON: Excel to JSON Converter with auto-detection and progress bar.",
epilog="Example: python xls2json.py data.xlsx -a -o output.json" # 에필로그 추가
)
parser.add_argument("excel_file", help="Path to the input Excel file.")
parser.add_argument(
"-s", "--sheet",
default=0,
help="Specify sheet name or 0-based index to convert (default: 0). Ignored if --all-sheets is used."
)
parser.add_argument(
"-a", "--all-sheets",
action='store_true',
help="Convert all sheets in the Excel file. Output JSON will be an object with sheet names as keys."
)
parser.add_argument(
"-o", "--output",
help="Path to the output JSON file. If not specified, output will be printed to the console."
)
args = parser.parse_args()
json_output = None
action_description = ""
if args.all_sheets:
action_description = "Convert all sheets with auto-detection"
json_output = convert_all_sheets_to_json(args.excel_file)
else:
sheet_identifier = args.sheet
try:
sheet_identifier_int = int(args.sheet)
sheet_identifier = sheet_identifier_int
except ValueError:
pass
action_description = f"Convert sheet '{sheet_identifier}' with auto-detection"
print(f"Processing: {action_description}...", file=sys.stderr)
json_output = convert_single_sheet_to_json(args.excel_file, sheet_name=sheet_identifier)
if json_output:
if args.output:
print(f"Saving results to '{args.output}'...", file=sys.stderr)
if save_to_file(json_output, args.output):
print(f"Success: {action_description} completed. Results saved to '{args.output}'.", file=sys.stderr)
else:
sys.exit(1)
else:
print(json_output) # Print JSON to stdout
else:
print(f"Error: Failed during '{action_description}'.", file=sys.stderr)
sys.exit(1)
if __name__ == "__main__":
main()
3. cmd를 켜고(Python 경로 Path에 포함되어있어야합니다) 다음과 같이 입력합니다(requirements.txt가 있는 경로에서)
pip install -r requirements.txt
4. 코드 상단에 사용방법과 같이 XLS2JSON을 사용해 주시면 됩니다.
# ==============================================================================
# XLS2JSON: Excel to JSON Converter
# ==============================================================================
#
# 설명:
# 이 스크립트는 Excel 파일(.xlsx, .xls)을 읽어 JSON 형식으로 변환하는
# 명령줄 인터페이스(CLI) 도구입니다. 데이터 시작 위치를 자동으로 감지하며,
# 특정 시트 또는 모든 시트를 변환하고, 결과를 콘솔 또는 파일로 출력할 수 있습니다.
# 여러 시트를 처리할 때 진행률 표시줄을 보여줍니다.
#
# 필요한 라이브러리 설치:
# pip install pandas openpyxl tqdm
#
# 기본 사용법:
# python xls2json.py <입력_Excel_파일경로> [옵션]
#
# 옵션:
# <입력_Excel_파일경로> : 변환할 Excel 파일의 경로 (필수)
#
# -o, --output <출력_파일경로> :
# 변환된 JSON 결과를 저장할 파일 경로입니다.
# 지정하지 않으면 결과가 콘솔(표준 출력)에 표시됩니다.
# 예: -o result.json
#
# -s, --sheet <시트_이름_또는_인덱스> :
# 변환할 특정 시트의 이름(문자열) 또는 0부터 시작하는 인덱스(숫자)입니다.
# 기본값은 0 (첫 번째 시트)입니다.
# --all-sheets 옵션이 사용되면 이 옵션은 무시됩니다.
# 예: -s "데이터 시트"
# 예: -s 1 (두 번째 시트를 의미)
#
# -a, --all-sheets :
# Excel 파일 내의 모든 시트를 변환합니다.
# 이 옵션을 사용하면 결과 JSON은 각 시트 이름을 키로 가지는 객체 형태가 됩니다.
# 예: {"Sheet1": [...], "Sheet2": [...]}
#
# 실행 예시:
# # 1. 첫 번째 시트를 콘솔에 출력
# python xls2json.py data.xlsx
#
# # 2. '매출데이터' 시트를 result.json 파일로 저장
# python xls2json.py data.xlsx -s "매출데이터" -o result.json
#
# # 3. 두 번째 시트(인덱스 1)를 console_output.json 파일로 저장
# python xls2json.py data.xlsx -s 1 -o console_output.json
#
# # 4. 모든 시트를 all_sheets.json 파일로 저장 (시트 이름별로 구분됨)
# python xls2json.py data.xlsx -a -o all_sheets.json
#
# ==============================================================================
문득 집에서 공부하다가 이런 프로그램이 로컬수준으로 있으면 좋을거 같다는 생각이 들어서 만들어보았습니다. python tkinter로 제작하였고, Java로 할라다가 코드가 너무 길어져서 짧게 치려는 느낌으로 만들었습니다.
* 무단배포는 금지합니다.(댓글달아주세용) * 기능에 커스터마이징이 필요하시다면 댓글달아주세용
사용법
프로그램의 화면은 위와 같습니다. 사용자는 캔버스 크기를 지정한다음에 이미지 추가로 여러이미지를 캔버스에 배치할 수 있습니다.(그러고 보니 DnD를 구현안했네요) 아무튼 이렇게 불러온 이미지는 캔버스 여러군데에 자유롭게 배치할 수 있습니다. 테두리나 각 사진들의 경계에 가면 자동으로 붙게끔 만들어보았고 배경사진이나 배경색도 선택할 수 있게 만들어 보았습니다.
다 된 사진은 캔버스 저장을 통해서 png파일로 저장할 수 있습니다.
아직 구현되지 않은 기능으로 사진 크기조절이랑 음... 또 뭐가 있으면 좋을까는 생각중입니다! 좋은 아이디어 있으신분은 알려주세요! (아이콘은 지정했는데 resource 로딩 오류같습니다. 혹시나 프로그램을 수정할 일이 생기면 반영해서 고치려구요!
* 숨겨진 기능인데, Shift를 누르고 여러사진을 한번에 이동시키거나 [Shift]+화살표로 미세이동 할 수 있습니다!
PC정비사 공부를 하면서 COMCBT 사이트에서 도움을 받고 있다. 우리나라 자격증의 특징인데, 문제은행식이어서 중복되는 문제들이 너무 많았다. 이를 제거해서 자주출제되었던 것들만 공부할 수 있으면 효율적이지 않을까 하는 생각에 코드를 만들었다. 코드는 다음과 같다.
import os
from PyPDF2 import PdfReader
location = ### 저장소 위치, 있는 폴더로 저장하세요 ###"
def extract(i) :
reader = PdfReader(i)
pages = len(reader.pages)
text = ""
for i in range(pages) :
text += reader.pages[i].extract_text()
return text
def duplicate_checker(l,cand) :
if(cand[0] in l and cand[1] in l and cand[2] in l) :
return True
if(cand[0] in l and cand[2] in l and cand[3] in l) :
return True
if(cand[0] in l and cand[3] in l ) :
return True
if(cand[1] in l and cand[2] in l ) :
return True
if(cand[1] in l and cand[3] in l ) :
return True
if(cand[2] in l and cand[3] in l ) :
return True
return False
def file_write(i,text) :
with open(str(i)+".txt","wt",encoding="UTF-8") as f:
f.write(text)
if __name__=="__main__" :
os.chdir(location)
try :
os.mkdir(r".\OUTPUT")
os.mkdir(r".\RAW")
except Exception as e:
pass
RAW_PDF_LIST = os.listdir(r".\RAW")
## Extract Code ##
dict_dat = dict()
count = 0
for i in RAW_PDF_LIST :
dict_dat[i] = extract(".\\RAW\\"+i)
file_write(".\\OUTPUT\\"+str(count),dict_dat[i])
count+=1
print(i," done")
## Dict Generate Code
PARSE_PDF_LIST = os.listdir(r".\OUTPUT")
STAT_Q = 0
STAT_A = 1
STAT_B = 2
STAT_C = 3
STAT_D = 4
cand_id_list = ["①","②","③","④"]
ans_id_list = ["❶","❷","❸","❹"]
qs = dict()
total_count = 0
for txt in PARSE_PDF_LIST :
data = list()
with open(".\\OUTPUT\\"+txt,"rt",encoding="UTF-8") as f :
lines = f.read().split("\n")
q_count = 0
question = ""
cand = ["","","",""]
answer = 0
cur_state = -1
for l in lines :
write_flag=False
if(l.strip() == "") :
continue
if(str(q_count+1)+". " in l) :
if(question != "") :
if(question not in qs) :
qs[question] = dict()
qs[question]["cand"] = cand
qs[question]["answer"] = answer
if("count" in qs[question]) :
qs[question]["count"] += 1
else :
qs[question]["count"] = 1
question = ""
cand = ["","","",""]
answer = 0
total_count +=1
question = l.split(str(q_count+1)+". ")[1].strip()
cur_state = STAT_Q
write_flag = True
if(cand_id_list[0] in l) :
cand[0] = l.split(cand_id_list[0])[1].split(cand_id_list[1])[0]
cand[0] = cand[0].split(ans_id_list[1])[0]
cur_state = STAT_A
write_flag = True
elif(ans_id_list[0] in l) :
cand[0] = l.split(ans_id_list[0])[1].split(cand_id_list[1])[0]
answer = 1
cur_state = STAT_A
write_flag = True
if(cand_id_list[1] in l) :
cand[1] = l.split(cand_id_list[1])[1].split(cand_id_list[2])[0]
cand[1] = cand[1].split(ans_id_list[2])[0]
cur_state = STAT_B
write_flag = True
elif(ans_id_list[1] in l) :
cand[1] = l.split(ans_id_list[1])[1].split(cand_id_list[2])[0]
answer = 2
cur_state = STAT_B
write_flag = True
if(cand_id_list[2] in l) :
cand[2] = l.split(cand_id_list[2])[1].split(cand_id_list[3])[0]
cand[2] = cand[2].split(ans_id_list[3])[0]
cur_state = STAT_C
write_flag = True
elif(ans_id_list[2] in l) :
cand[2] = l.split(ans_id_list[2])[1].split(cand_id_list[3])[0]
answer = 3
cur_state = STAT_C
write_flag = True
if(cand_id_list[3] in l) :
cand[3] = l.split(cand_id_list[3])[1]
cur_state = STAT_D
write_flag = True
q_count+=1
elif(ans_id_list[3] in l) :
cand[3] = l.split(ans_id_list[3])[1]
answer = 4
cur_state = STAT_D
write_flag = True
q_count+=1
if(write_flag==False) :
if(cur_state==STAT_Q) :
question+= l
elif(cur_state==STAT_A) :
cand[0] += l
elif(cur_state==STAT_B) :
cand[1] += l
elif(cur_state==STAT_C) :
cand[2] += l
elif(cur_state==STAT_D) :
cand[3] += l
qs_sorted = sorted(qs.items(),key = lambda x:x[1]["count"],reverse=True)
with open("OUTPUT.txt","wt",encoding="utf-8") as f:
f.write("#### TARGET FILE ####\n")
for l in RAW_PDF_LIST :
f.write(l+"\n")
f.write("\n")
f.write("Total Question : "+str(total_count)+"\n\n")
f.write("Trimmed Question : "+str(len(qs_sorted))+"\n\n")
f.write("\n")
f.write("### EXAM LINE ###\n")
for v in qs_sorted :
f.write("Question : "+v[0]+" ## Count : "+str(v[1]["count"])+"\n\n")
f.write("1. "+v[1]["cand"][0]+"\n")
f.write("2. "+v[1]["cand"][1]+"\n")
f.write("3. "+v[1]["cand"][2]+"\n")
f.write("4. "+v[1]["cand"][3]+"\n\n")
f.write("Answer : "+str(v[1]["answer"]))
f.write("\n\n\n")
print("PARSE FINISH")
조금 비효율적인 조건문이 있으나, 알바없다.... 사용방법은 폴더아래 RAW라는 폴더를 만들고, 그 안에 comcbt.com에서 다운로드 받은 교사용.pdf를 넣어두고 코드를 실행하면 끝이다. 중복된 문제들을 제외하고, 나왔던 빈도수의 내림차순으로 output.txt가 생성된다.
* 참고사항
1. 텍스트만 추출했기 때문에, 그림문제는 정상적으로 안보인다.
2. 이유는 모르겠는데, 번호를 구분하는 ① 이런게 한줄에 엄청 많으면 그 파일을 불러오는데 실패한다. 필요하면 나중에 고치지 뭐;
시현입니다. 아직 미완인데, 귀차니즘으로 잠깐 정지해두고 다른 공부하다 오려그럽니다. 일전에 스크립트를 포스팅하였으나, 뭐하는 짓인가 싶어 비공개로 돌렸습니다.
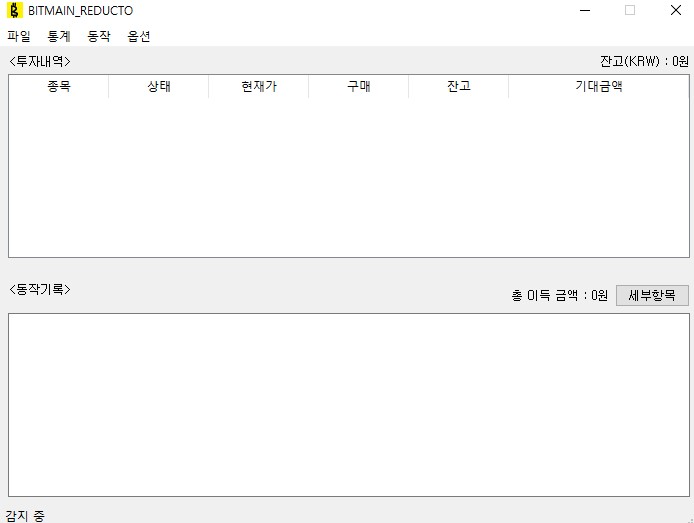
프로그램은 사용자가 진입, 구매, 판매조건을 설정하여 그 조건에 맞게 트레이드로봇이 동작하는 구조입니다
MainWindow
기본 화면 구성은 다음과 같다.
위쪽에 menu들은 다음과 같은 하위 항목이 있다.
프로그램은 아래와 같이 tray_icon에 표시되며, 24시간 돌아가야 되는 특성상 X버튼을 눌러도 꺼지지 않고, main 화면만 invisible된다.
SubWindow
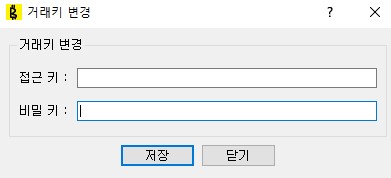
1. 거래키 Window
필자의 KEY가 기본으로 들어있어 지우고 사진을 올렸다. 로컬파일인 key.dat을 로딩해서 보여준다.
2. 전체 잔고 확인 Window
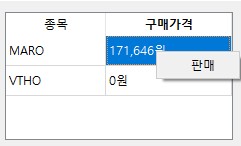
가지고 있는 코인을 보여주며, 우클릭으로 판매할 수 있다.(어... VTHO쟨 뭐지?)
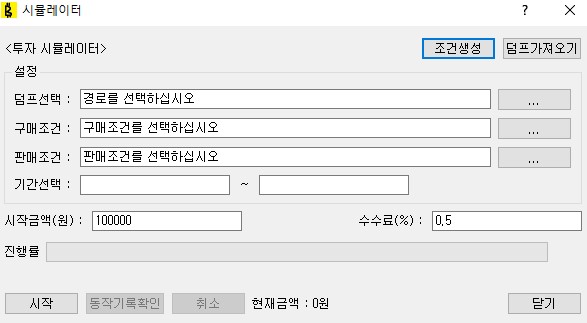
3. 시뮬레이터
과거 데이터를 기준으로 구매/판매 조건이 어떤 결과를 가져올지 시뮬레이팅하는 기능이다. 당연히 과거데이터가 한정되어있어 약간의 차이가 존재한다.(upbit에서 ohlcv를 길게 요구하면 중간중간 빠지는 경우가 있더라)
(아... 이거 만들겠다는 생각만 안했으면,... 차라리 안정성이나 늘려두지...)
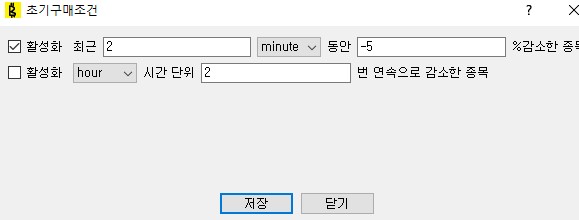
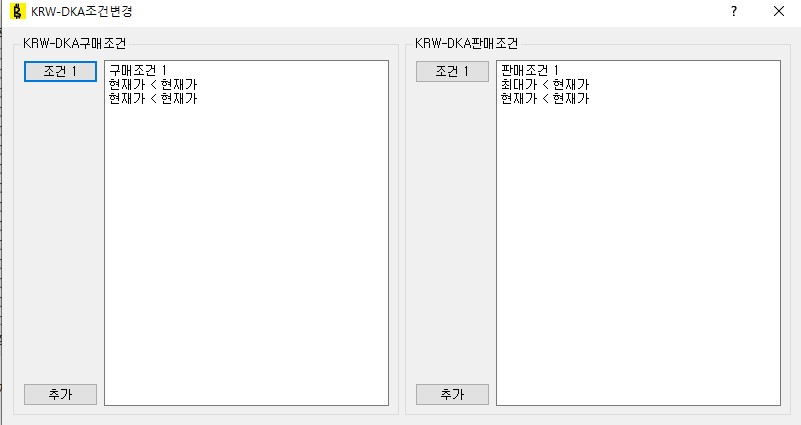
조건생성을 클릭하면 다음과 같이 구매 / 판매조건을 걸어줄 수 있다. 옆에 [...]버튼을 눌러서 기존 조건을 가져올 수도 있다. 동작중인 조건은 ./criteria 폴더아래 [코인명]_[buy/sell]_criteria.dat로 저장되어 있다.
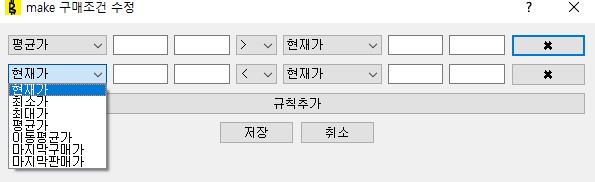
조건을 클릭하면 다음과 같이 편집할 수 있다.
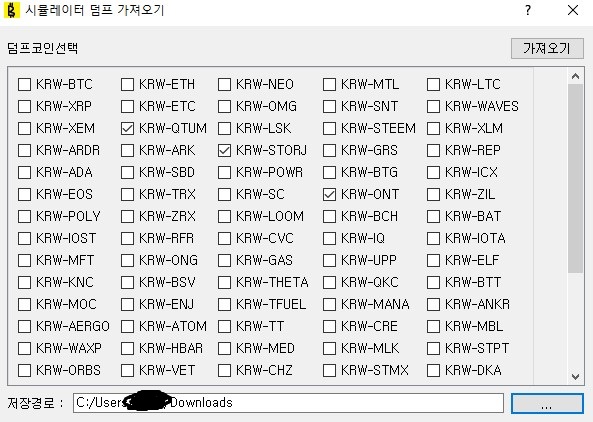
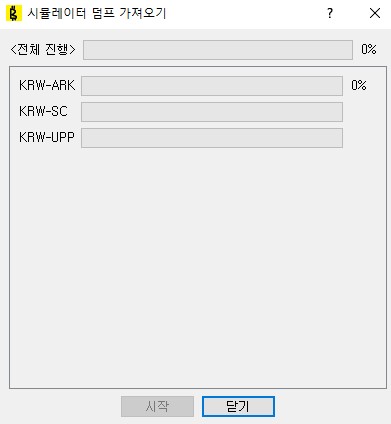
과거데이터 덤프를 가져오는 화면은 아래와 같다. 궁금한 종목을 가져오고 [가져오기]버튼을 눌러 가져올 수 있다.
가져온 데이터는 ./dump 아래 [코인명].dump로 저장된다.
4. 진입 조건 Window
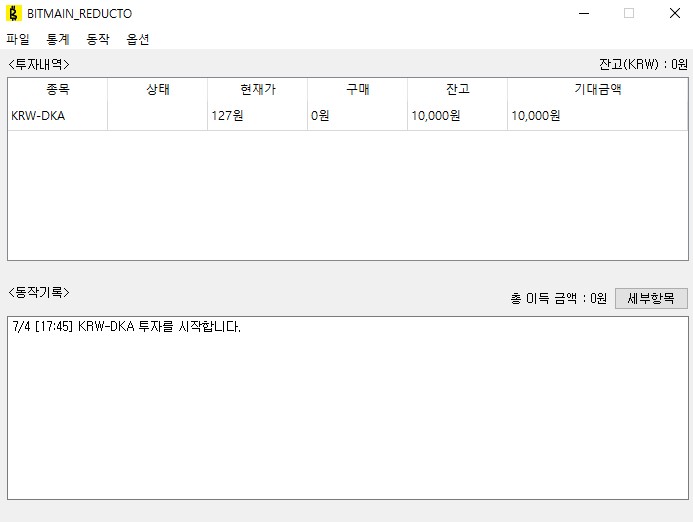
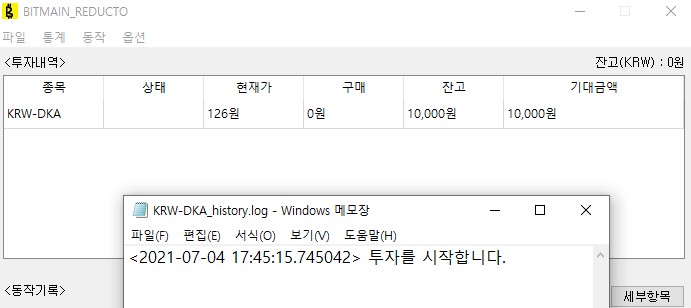
현재 진입조건으로는 2가지 경우를 만들어 두었다. 업데이트하고 조금 손보면 더 늘어날 예정이다. 글을 쓰는 현재 2분동안 -5%감소한 종목이 없는지 좀처럼 시작을 안해서 2일동안 5%감소한 항목으로 조건을 바꾸어 하나를 시작 시켰다.
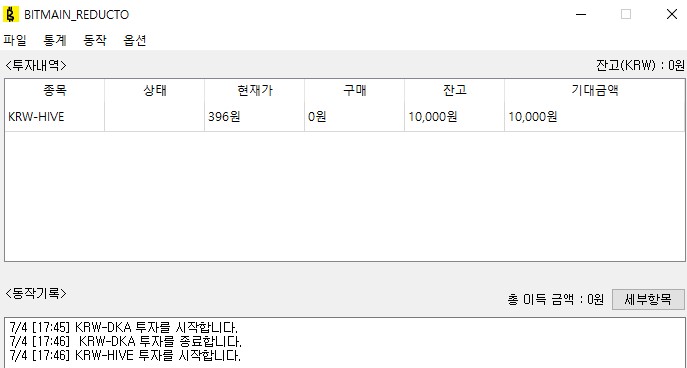
짜잔.
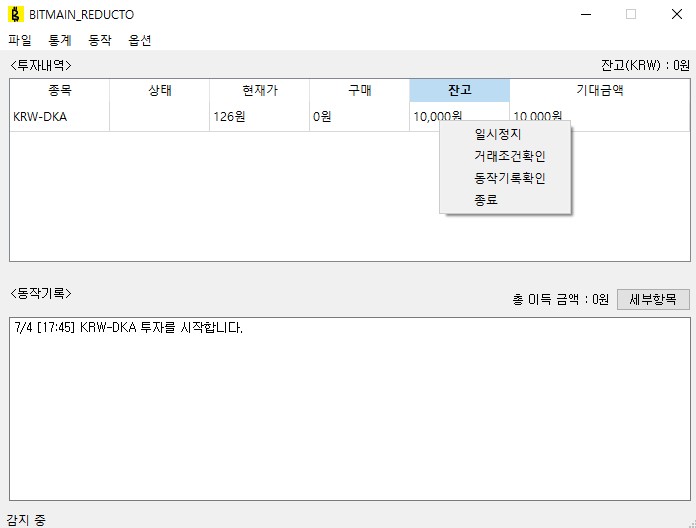
저 한 행이 트레이딩봇 한 개이다. 우클릭하면 트레이딩 봇에 대한 동작 기록 확인 / 거래 조건 변경 / 강제 종료 / 일시정지등을 지시할 수 있다.
거래조건확인은 시뮬레이팅에서 본 그 화면과 동일하다. 단 window이름이 코인명으로 지정되어있는데, 글로벌 프리셋에서 복사되어 코인별로 조건을 따로따로 지정하는 동작이다. 현재는 거래가 안되게끔 현재가<현재가로 걸어두었다.
동작기록은 메모장으로 [코인명]_history.log가 열린다. 이 파일은 ./var/log 아래 일자별로 폴더가 생성된다.
마지막으로 강제종료하여 해당 트레이드 봇을 강제종료 시켰다.(...응? 이상한게 하나 시작되었다.)
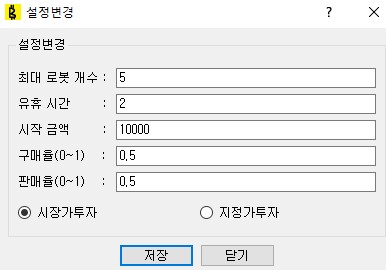
5. 설정변경 window
프로그램의 동작 설정을 변경할 수 있는 window이다.
Q. 왜 잔고(KRW)가 0인데 시작하나요?
A. 프로그램 테스트 용도로 가짜 돈이 조금 들어가 있습니다.
Q. 남은 개발항목은 어떤게 있나요?
A. 시뮬레이팅 결과화면이 아직 덜 준비되었습니다. 그 외 프로그램의 사용기간 제한이나, 제작자에게 e-mail건의 등을 하는 기능이 미구현상태이고, 전체적으로 안정성을 늘려야합니다. 디버깅없이 열심히 삘받아서 코딩한거라 잔 오류가 조금씩 보이네요. 가능하다면 UI도 조금 꾸미고 싶어요.