Python Challenge 24의 Url은 다음과 같다
Python challenge 24 : http://www.pythonchallenge.com/pc/hex/ambiguity.html
구성

오우! 쒰! 미로다. 픽셀이 깨져 보이는 지경에 이르렀다. 일단 특별한 점이 안 보인다. 주석에도 특별한 게 안 보인다. 다운로드한 사진의 이름이 maze.png인 걸로 봐서 미로를 풀어야 되는 거 같다.
해결 아이디어
우선 미로라면 당연히 미로의 시작과 끝이 있을 것이다. 그거부터 찾아보자. 기본적인 아이디어는 경계선에 끝과 끝에 있을 것으로 생각이 된다.
### 24_1.py
from PIL import Image
if __name__=="__main__" :
img = Image.open("maze.png")
for x in range(img.width) :
bottom = img.getpixel((x,img.height-1))
entry = img.getpixel((x,0))
print(entry,bottom)
for y in range(img.height) :
left = img.getpixel((img.width.0))
right = img.getpixel((img.width-1,y))
print(left,right)그렇긴 한데 허허허... 이미지가 너무 크다. (255,255,255,255)가 벽인걸로 보이니까 그걸 빼고 탐색을 해보자.
### 24_2.py
from PIL import Image
if __name__=="__main__" :
img = Image.open("maze.png")
wall = (255,255,255,255)
for x in range(img.width) :
bottom = img.getpixel((x,img.height-1))
top = img.getpixel((x,0))
if(bottom!=wall or top!=wall) :
print(x, top, bottom)
for y in range(img.height) :
left = img.getpixel((img.width,0))
right = img.getpixel((img.width-1,y))
if(left != wall or right != wall) :
print(y,left,right)결과로 나온 값중에 (0,0,0,255)인 값이 있다. top, bottom의 (width-2, 0) 와 (1, height-1)이다. 일단 미로를 풀어야 되는 건 맞는 거 같다. 미로 값들의 픽셀을 구해서 배열에 넣어보자.
탐색 알고리즘의 가장 대표적인 2가지 BFS와 DFS 중에 미로를 탐색하기 좋은 알고리즘은 BFS이다. 그래 코드 한번 짜봦
### 24_2.py
from PIL import Image
import queue
def bfs_check(pos,max_x,max_y,alr) :
if(pos[0]>=0 and pos[0]<max_x and
pos[1]>=0 and pos[1]<max_y and
pos not in alr) :
return True
else :
return False
if __name__=="__main__" :
img = Image.open("maze.png")
d = [(0,1),(0,-1),(1,0),(-1,0)]
width, height = img.size
wall = (255,255,255,255)
ent = (width-2,0)
ext = (1,height-1)
print(img.getpixel(ent),img.getpixel(ext))
cur_q = queue.Queue()
cur_q.put(ext)
ans_dict = dict()
while(cur_q.empty()==False) :
cur_pos = cur_q.get()
if(cur_pos == ent) :
break
for a in d :
next_pos = (cur_pos[0] + a[0], cur_pos[1] + a[1])
if(bfs_check(next_pos,width,height,ans_dict)) :
if(img.getpixel(next_pos) != (255,255,255,255)) :
ans_dict[next_pos] = cur_pos
cur_q.put(next_pos)
ans = list()
while(cur_pos!=ext) :
ans.append(img.getpixel(cur_pos))
cur_pos = ans_dict[cur_pos]자 코드가 길다고 볼 수도 있는데, 필자같이 파이선을 잘 못하는 사람들을 위해서 플로우 차트를 그려주겠다. 다음과 같다.
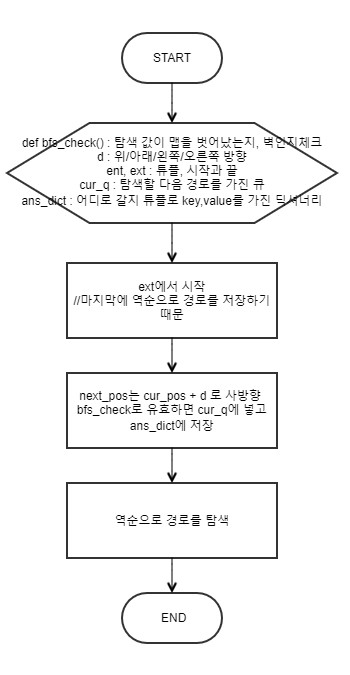
그런데, 경로를 탐색하다 보면 다음과 같은 특징이 있다.
- 픽셀은 (n,0,0,255)로 이루어져 있다. n은 모른다. 1 <n <255의 값이다.
- 맨 처음 다음부터 홀수번째에만 n이 값이 있다. 짝수는 0이다.
그래서 그 값들을 보면 PK로 시작을 한다. (zip 파일의 헤더) 따라서 byte로 변환을 하기 위한 코드를 다음과 같이 작성하자
### 24_3.py
from PIL import Image
import queue
def bfs_check(pos,max_x,max_y,alr) :
if(pos[0]>=0 and pos[0]<max_x and
pos[1]>=0 and pos[1]<max_y and
pos not in alr) :
return True
else :
return False
if __name__=="__main__" :
img = Image.open("maze.png")
d = [(0,1),(0,-1),(1,0),(-1,0)]
width, height = img.size
wall = (255,255,255,255)
ent = (width-2,0)
ext = (1,height-1)
print(img.getpixel(ent),img.getpixel(ext))
cur_q = queue.Queue()
cur_q.put(ext)
ans_dict = dict()
while(cur_q.empty()==False) :
cur_pos = cur_q.get()
if(cur_pos == ent) :
break
for a in d :
next_pos = (cur_pos[0] + a[0], cur_pos[1] + a[1])
if(bfs_check(next_pos,width,height,ans_dict)) :
if(img.getpixel(next_pos) != (255,255,255,255)) :
ans_dict[next_pos] = cur_pos
cur_q.put(next_pos)
ans = list()
while(cur_pos!=ext) :
ans.append(img.getpixel(cur_pos)[0])
cur_pos = ans_dict[cur_pos]
ans = ans[1::2]
with open("24","wb") as f:
f.write(bytearray(ans))
img.close()성공이다. 24.zip을 압축 해제하면 lake라는 사진과 mybroken이라는 압축파일이 나온다.

일단 풀었다. lake 찾았다.
Answer Url : http://www.pythonchallenge.com/pc/hex/lake.html
'Python > Python Challenge' 카테고리의 다른 글
| [Python Challenge 26] 과거의 행실을 돌아보세요 (0) | 2021.06.06 |
|---|---|
| [Python Challenge 25] 퍼즐맞추기 (0) | 2021.06.06 |
| [Python Challenge 23] 보너스 타임! 기본으로 돌아갈 때 (0) | 2021.06.05 |
| [Python Challenge 22] 조이콘은 비쌉니다. (0) | 2021.06.05 |
| [Python Challenge 21] 압축효율 끝판왕 (0) | 2021.06.05 |