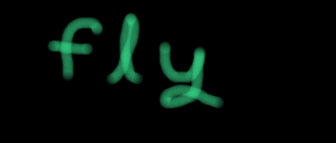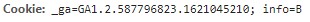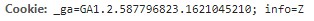Python Challenge 20의 Url은 다음과 같다
Python challenge 20 : http://www.pythonchallenge.com/pc/hex/idiot2.html
구성

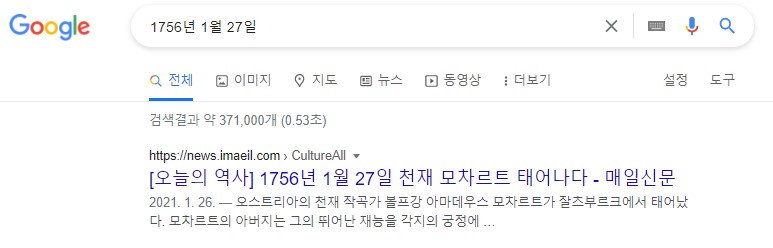
영어로는 표지판에
"이 울타리 뒤쪽으로는 사유재산입니다."
라고 쓰여 있다. 아래 영어는
"그래도 주의깊게 살펴보는 것은 허용됩니다."
라고 적혀있다.
우선 특별한 점이 없으니 파일을 검사해보자. unreal.jpg로 다운로드되는 파일은 헤더 변조도 없어 보이고, 특별히 숨겨놓은 스트링값도 없어 보인다... 으흠; 주석을 볼까
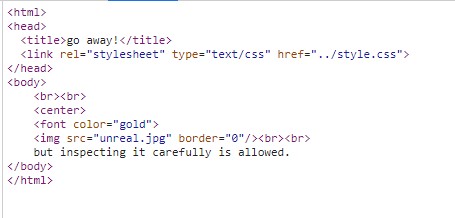
주석도 특별한게 없다. 난항이 될 거 같다.
해결 아이디어
우선 이 문제를 해결하기 위해서는 헤더를 주의 깊게 쳐다볼 필요가 있다.
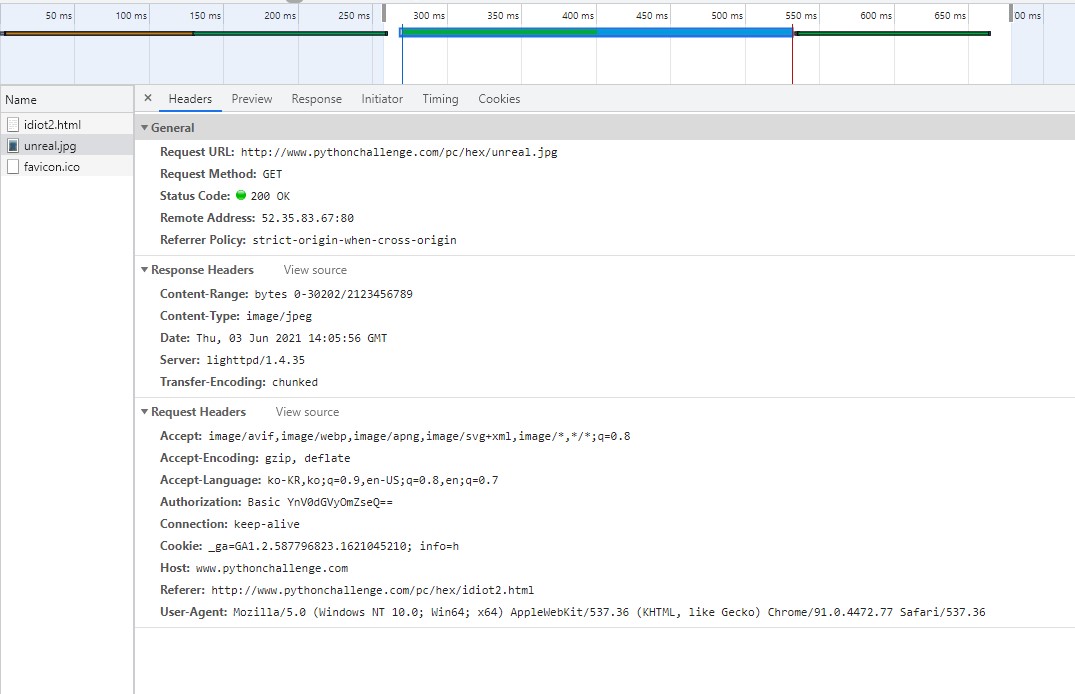
여러분과 필자가 보고 있는 이 요청정보는 idiot2.html이 아닌 unreal.jpg의 정보라는 것을 기반으로 잡고 가자. 자세히 보면 독특한 response header가 보인다. 바로 content-range라는 응답인데, 이게 전체 크기인 2123456789에서(참 대충도 짓는다. 아마 2의 32 제곱 만들고 싶었던 듯) 0-30202 bytes만을 가져온다.
원래 이런 식이라면 HTTP코드는 206(partial content)이 되어야 한다.(그래야 나머지 데이터도 수신받을 수 있다.) 그러나 304(not modified)로 되었다는 것은 우리한테 모든 정보가 전달되지 않고 강제로 종료시켰다는 의심을 할 수 있다. HTTP코드를 자세하게 모르시는 분들은 아래를 확인하자
https://developer.mozilla.org/ko/docs/Web/HTTP/Status
HTTP 상태 코드 - HTTP | MDN
HTTP 응답 상태 코드는 특정 HTTP 요청이 성공적으로 완료되었는지 알려줍니다. 응답은 5개의 그룹으로 나누어집니다: 정보를 제공하는 응답, 성공적인 응답, 리다이렉트, 클라이언트 에러, 그리고
developer.mozilla.org
일단 30202 뒤쪽으로 해서 콘텐츠를 더 받을 수 있도록 코드를 작성해 보자
### 20_1.py from requests import * if __name__=="__main__" : header = {"Authorization" : "Basic YnV0dGVyOmZseQ==", "user-agent" : "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.77 Safari/537.36", "Range": "bytes=30203-/2123456789" } url = "http://www.pythonchallenge.com/pc/hex/unreal.jpg" res = get(url,headers=header) 아참, 지난 시간까지는 requests 모듈의 get이나 post함수에 auth()라는 파라미터를 주었는데 이번에는 헤더에 base64로 butter:fly값이 인코딩 된 값을 Authorization으로 쓰고 있다.(왜 그러냐고? 모른다. 기존 헤더를 보니 그랬다.)
결과는 다음과 같다.
>>> res.headers {'Content-Type': 'application/octet-stream', 'Content-Transfer-Encoding': 'binary', 'Content-Range': 'bytes 30203-30236/2123456789', 'Transfer-Encoding': 'chunked', 'Date': 'Thu, 03 Jun 2021 14:11:29 GMT', 'Server': 'lighttpd/1.4.35'} >>> res.text "Why don't you respect my privacy?\n"오호; 다음 값은 30237~ 부터 있는 것이 자명하다. 계속해서 요청해 보면 각각의 범위에서 다음과 같은 값을 찾을 수 있다.
- 0-30202 : unreal.jpg
- 30203-30236 : "Why don't you respect my privacy?\n"
- 30237-30283 : 'we can go on in this way for really long time.\n'
- 30284-30294 : 'stop this!\n'
- 30295-30312 : 'invader! invader!\n'
- 30313-30346 : 'ok, invader. you are inside now. \n'
- 30347-? : ''
그만 오라고 열심히 설명하다가 30347bytes부터 그만두고 ''만 나온다. 맨 뒤쪽을 검색을 해보면
- 2123456744-2123456788 : 'esrever ni emankcin wen ruoy si drowssap eht\n'
응? 이상한 언어가 나온다. 우리가 거꾸로 뒤에서부터 탐색을 하는 거 니까, 글자도 거꾸로 나왔다. ㅋㅋㅋㅋ 무슨 콘셉트질인지... 거꾸로 읽어 보자.
'the password is your new nickname in reverse'
와우! 우리의 NICKNAME은? butter? 아니다 아니다 위에서 우리 보고 invader라고 말하지 않는가. 일단 password가 invader의 반대말인 redavni인 것을 알고 넘어가자 우리 보고 invader라고 한 것이 화나니 조금만 더 뒤로 찾아보자
- 2123456712-2123456743 : 'and it is hiding at 1152983631.\n'
나이스 이제 좀 유의미한 인덱스를 주는 거 같다. 이동해보자
- 1152983631-1153223363 : some byte file
일단 파일 사이즈가 늘었다. 한번 콘텐츠를 다운로드하여보자
### 20_2.py from requests import * if __name__=="__main__" : header = {"Authorization" : "Basic YnV0dGVyOmZseQ==", "user-agent" : "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.77 Safari/537.36", "Range": "bytes=1152983631-/2123456789" } url = "http://www.pythonchallenge.com/pc/hex/unreal.jpg" res = get(url,headers=header) with open("somefile","wb") as f: f.write(res.content)
그래서 다운로드한 somefile를 hxd로 뜯어보자

헤더 시그니처를 보니 ZIP 파일이다. 503B0304는 국 룰이다.
zip으로 변경해서 압축해제를 하려면 비밀번호를 요구한다. 그래 그 비밀번호
Answer PW : redavni
아 조금 독특한건 압축해제한 파일에 readme를 보면 우리는 이미 20번문제는 해결한 상태라고한다. 이제 같이 압축이 풀린 .pack을 해결하는게 22번 문제라고 한다.
'Python > Python Challenge' 카테고리의 다른 글
| [Python Challenge 22] 조이콘은 비쌉니다. (0) | 2021.06.05 |
|---|---|
| [Python Challenge 21] 압축효율 끝판왕 (0) | 2021.06.05 |
| [Python Challenge 19] You are An Idiot! (0) | 2021.06.03 |
| [Python Challenge 18] 즐거운 다른그림찾기놀이 (0) | 2021.06.02 |
| [Python Challenge 17] 얘 이것도 가져가렴 (0) | 2021.05.30 |