마이크로 아키텍처
마이크로 아키텍처 혹은 CPU 아키텍처는 CPU 또는 이와 관련된 디지털 신호 처리기의 회로다. 기본적으로 CPU가 처리하는 일이 함수의 읽음 -> 해석 -> 실행 -> 결과기록이었던 것을 생각해보면 이것이 매우 세부적인 수준에서 기술되어있는 것이 마이크로 아키텍처라고 칭할 수 있겠다. 이것은 CPU 제조사 마다 달라지는데, 대중적인 CPU 종류는 다음과 같다

병렬처리
CPU는 그 높은 연산능력을 바탕으로 빠르게 지정된 연산을 수행한 후에 결과를 반환하는 소자이다. 병렬처리는 몇몇 명령어의 구조적인 최적화 등 일련의 방법을 통해서 명령어를 동시에 수행하는 기법이다. 대표적인 병렬처리 방식인 파이프라인 / 슈퍼스칼라를 알아보도록 하자
병렬처리 – 파이프라인(Pipeline)
명령어 파이프라인(Instruction Pipeline)은 명령어를 읽어 순차적으로 실행하는 프로세서에 적용되는 기술이다. 다음의 도표를 보자
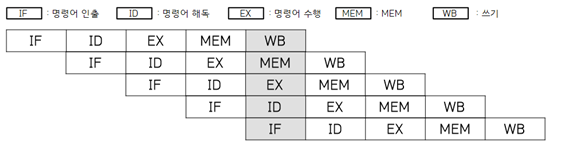
꽤 직관적인 그림인데, 한 개의 행을 하나의 명령어로 볼 때 그 명령어들을 여러개의 단계로 구분하고 다음 명령어의 처리를 기다린다면 다른 명령어의 다른 단계를 수행하는 방식인 것이다. 위에사진은 명령어를 기반으로 구분되어있는데, CPU 클록 주기에 맞추어 더욱 병렬성을 높인 슈퍼파이프라인 방식도 존재한다.
병렬처리 – 슈퍼스칼라(SuperScala)
파이프라인이 그래도 한번에는 같은 스텝의 하나의 명령어를 수행한다면 슈퍼스칼라방식은 애초에 명령어를 처리할 수 있는 스레드를 여러가지 사용하는 방식이다.
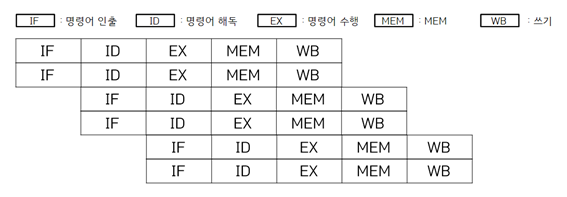
다른 기법으로 VLIW(Very Long Instruction Word)가 있다. 동시 실행 가능한 여러 가지의 명령을 하나의 긴 명령으로 재 배열하여 처리하는 방식이다.(명령어의 합성)
파이프라인 해저드
파이프라인 해저드(Hazard)라는 용어가 있다. 병렬처리기법을 사용함에도 불구하고 오히려 속도가 저하되는 현상인데, 의존성이나, 순서등에 의해서 발생하며 데이터 해저드(명령어 의존성으로 발생), 제어 위험(순서에 의한 발생), 구조적위험(자원 동시 접근에 의한 위험) 으로 구분된다.
이러한 파이프라인 해저드는 어느정도는 보완할 수 있다. 예를 들면 최근에 발생한 분기의 결과를 토대로(분기 역사표) 다음의 분기를 예측하여 데이터/제어의 해저드를 어느정도 극복하는 방식이 있겠다.
정리
이번시간에는 CPU의 구조를 기술하는 마이크로 아키텍처의 개념과 여러 가지 병렬처리 기법 및 파이프라인의 해저드까지 간단하게 알아보았다.
다음시간에는
메모리 계층구조에대해서 알아보자
'자격 > 임베디드기사' 카테고리의 다른 글
| [임베디드기사] [필기] 버스와 입출력장치 (0) | 2023.08.21 |
|---|---|
| [임베디드기사] [필기] 메모리 계층구조 / 가상메모리 / 캐시메모리 (0) | 2023.08.17 |
| [임베디드기사] [필기] CPU와 마이크로프로세서 – 구조, 명령어 셋 (0) | 2023.08.16 |
| [임베디드기사] [필기] 프로그래머블 로직 - HDL (0) | 2023.08.16 |
| [임베디드기사] [필기] 기억소자 - 메모리(Memory) (0) | 2023.08.14 |